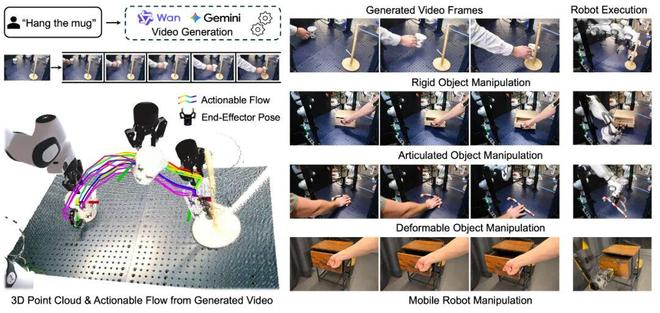
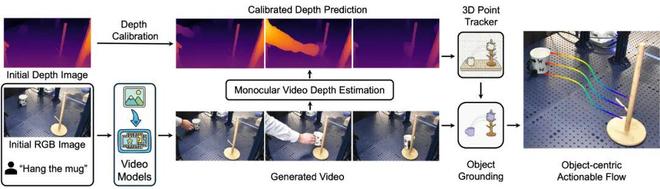
这个模块的目标是,根据用户输入的一句自然语言指令和一张初始场景的 RGB-D 图像,生成目标物体的 3D 动作流。整个过程无需任何人工干预,完全由一系列预训练好的视觉模型完成。
图 2:动作流生成器。从初始图像和文本提示生成视频,再通过一系列视觉模块将其提炼为以对象为中心的 3D 可执行流。
1.视频生成:首先,使用像 通义万相 或 可灵 AI 这样的 SOTA 视频生成模型,根据初始图像和文本指令(如 “打开抽屉”)生成一段几秒钟的视频。
https://mp.weixin.qq.com/s/qolvGDUY22luJYzmq07tgw
2.2D 到 3D 提升:由于生成的视频是 2D 的,而我们在 3D 世界中执行任务,我们需要将 2D 信息提升到 3D 空间。NovaFlow 通过单目视频深度估计算法,为视频的每一帧生成对应的深度图。由于单目深度估计模型会产生系统性误差,研究团队额外利用了第一帧真实的深度图来对估计的单目深度视频进行校准。
3.3D 点追踪:在有了 3D 视频后,使用 3D 点追踪模型,密集地追踪视频中每一个点在三维空间中的运动轨迹。
4.对象分割与提取:上一步追踪了整个场景的运动。为了得到 “对象” 的动作流,NovaFlow 使用开放词汇的对象检测和分割模型(如 Grounded-SAM2),将视频中的目标物体(如抽屉)从背景中分割出来。最后,只保留属于该物体的运动轨迹,就得到了最终的、纯净的 “可执行 3D 对象流”。

 发表于 2025-10-9 14:05:04
发表于 2025-10-9 14:05:04