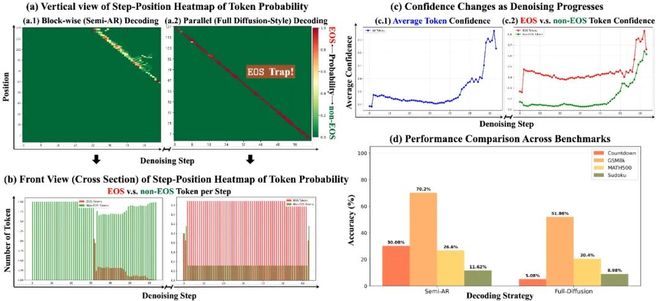
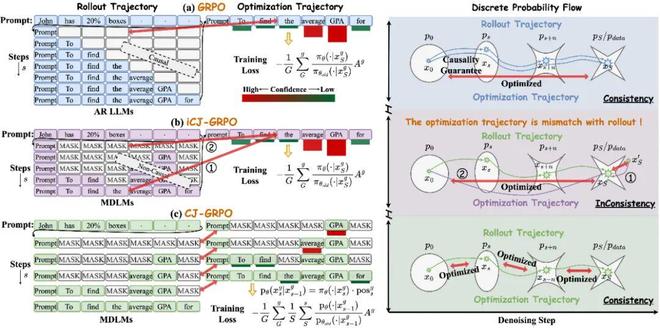
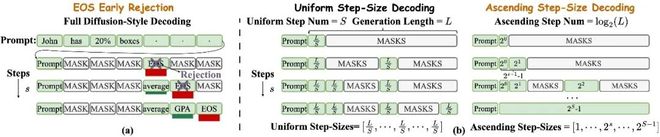
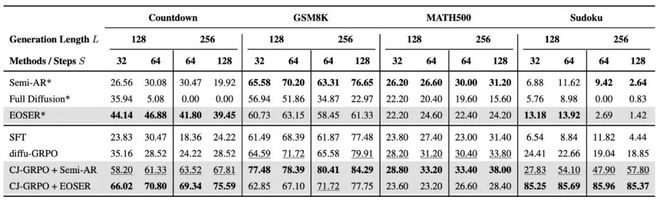
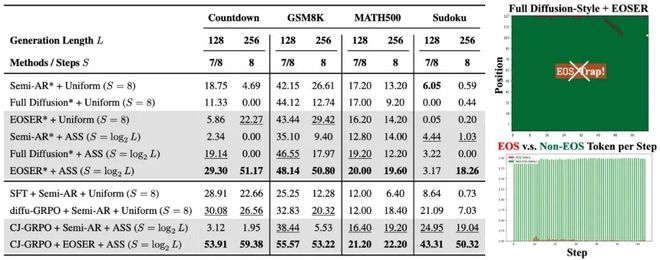
近期,复旦大学、上海人工智能实验室、上海交通大学联合研究团队发布最新论文《Taming Masked Diffusion Language Models via Consistency Trajectory Reinforcement Learning with Fewer Decoding Step》。
他们提出了一套对于掩码扩散大语言模型(Masked Diffusion Large Language Model,MDLM)的高效解码策略 + 强化学习训练组合,显著提升了掩码扩散大语言模型的推理性能与效率,为扩散大语言模型的发展开辟了新路径。

 发表于 2025-11-6 06:59:54
发表于 2025-11-6 06:59:54